
Obliczanie odchylenia standardowego w Excelu to jedna z tych czynności, które wyglądają technicznie, a w praktyce pomagają szybko ocenić rozrzut wyników, stabilność pomiarów albo zmienność sprzedaży. W arkuszu da się to zrobić bardzo sprawnie, ale trzeba dobrać właściwą funkcję i poprawnie odróżnić próbkę od całej populacji. Poniżej pokazuję, jak policzyć wynik krok po kroku, kiedy użyć której formuły i jak nie wpaść w najczęstsze pułapki.
Najkrótsza wersja, którą warto zapamiętać od razu
- Do próby użyj ODCH.STANDARD.PRÓBKI albo starszej ODCH.STANDARDOWE.
- Do całej populacji użyj ODCH.STANDARD.POPUL.
- W polskiej wersji Excela argumenty w formule zwykle rozdziela się średnikami.
- Jeśli zakres zawiera tekst lub wartości logiczne, zwykłe funkcje je pomijają, a wersje z końcówką .A mogą je uwzględnić.
- Sam wynik trzeba czytać razem ze średnią i skalą danych, bo liczba bez kontekstu łatwo myli.
Którą funkcję w Excelu wybrać
Najwięcej błędów zaczyna się nie od samego obliczenia, ale od złego wyboru funkcji. Microsoft w aktualnym Excelu promuje nazwy ODCH.STANDARD.PRÓBKI i ODCH.STANDARD.POPUL, a starsze odpowiedniki nadal spotkasz w dawnych plikach i materiałach szkoleniowych. Ja zwykle zaczynam od prostego pytania: czy analizuję część danych, czy cały zbiór, który naprawdę chcę opisać?
| Funkcja w polskim Excelu | Odpowiednik angielski | Kiedy jej użyć | Co robi |
|---|---|---|---|
| ODCH.STANDARD.PRÓBKI | STDEV.S | Gdy dane są próbką, np. 20 wyników z większego zbioru | Stosuje korektę n-1 i ignoruje tekst oraz wartości logiczne w zakresie |
| ODCH.STANDARD.POPUL | STDEV.P | Gdy masz całą populację, np. pełny rejestr za konkretny okres | Dzieli przez n, bo opisuje rozrzut całego zbioru, a nie go estymuje |
| ODCH.STANDARDOWE.A | STDEVA | Gdy w danych chcesz uwzględnić także tekst i wartości logiczne | Liczy liczby, tekstowe reprezentacje liczb oraz wartości logiczne |
| ODCH.STANDARD.POPUL.A | STDEVPA | Gdy liczysz populację i masz mieszane dane | Działa jak wersja populacyjna, ale uwzględnia też dane nieliczbowe z zakresu |
W starych arkuszach możesz jeszcze trafić na ODCH.STANDARDOWE jako dawną nazwę dla próby. W praktyce najbezpieczniej jest jednak przechodzić na nowsze nazwy, bo są czytelniejsze i lepiej pokazują, co dokładnie liczysz. Gdy już wiesz, którą funkcję wybrać, najprościej policzyć wynik bezpośrednio na zakresie komórek.
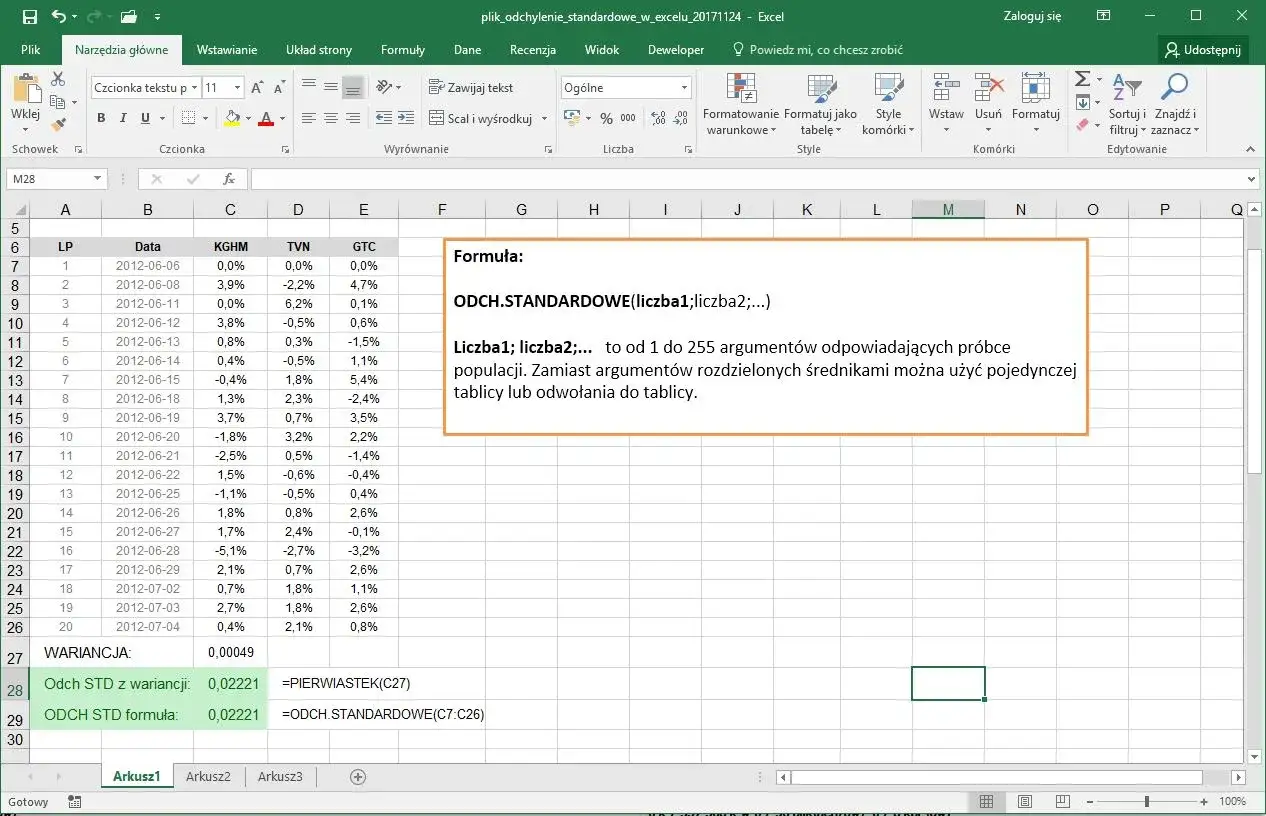
Jak policzyć wynik krok po kroku w arkuszu
W polskim Excelu formuła jest krótka, ale ważne są szczegóły: zakres komórek, średniki i właściwa nazwa funkcji. Jeśli masz dane w kolumnie od A2 do A11, wpisz po prostu =ODCH.STANDARD.PRÓBKI(A2:A11) albo, gdy pracujesz na całej populacji, =ODCH.STANDARD.POPUL(A2:A11).
- Wpisz dane liczbowe do jednej kolumny albo jednego wiersza, bez przypadkowych pustych komórek w środku zakresu.
- Kliknij pustą komórkę, w której ma pojawić się wynik.
- Wpisz formułę z odpowiednią funkcją i zakresem, na przykład
=ODCH.STANDARD.PRÓBKI(B2:B12). - Zatwierdź formułę klawiszem Enter.
- Jeśli liczba ma trafić do raportu, ustaw czytelny format, zwykle 2 lub 3 miejsca po przecinku.
Na przykładzie z dokumentacji Microsoftu ten sam zestaw 10 wartości daje 27,46392 dla próby i 26,05456 dla całej populacji. To dobrze pokazuje, że różnica między wariantami nie jest kosmetyczna, tylko wynika z innego założenia statystycznego. Sama formuła jest prosta, ale najważniejsze jest jeszcze dobre rozróżnienie próby i populacji.
Próbka czy cała populacja
To rozróżnienie ma większe znaczenie, niż widać na pierwszy rzut oka. Jeśli analizujesz tylko część danych, Excel powinien potraktować je jako próbkę. Jeśli masz cały zbiór, który naprawdę chcesz opisać, wybierasz wariant populacyjny. W praktyce chodzi o odpowiedź na pytanie: czy ten zakres to całość zjawiska, czy tylko jego fragment?
Kiedy mówimy o próbce
Próbką będzie na przykład 30 ankiet z kilku tysięcy klientów, 12 pomiarów z większej serii produkcyjnej albo wycinek sprzedaży z jednego miesiąca, jeśli chcesz wyciągać wnioski o szerszym procesie. W takich sytuacjach wariant dla próby jest właściwy, bo estymuje rozrzut całej populacji na podstawie części danych.
Przeczytaj również: Jak zrobić enter w komórce Excel i poprawić formatowanie tekstu
Kiedy mówimy o populacji
Populacja to pełny komplet danych, który rzeczywiście chcesz opisać: wszystkie oceny z danego semestru, jeśli analizujesz właśnie ten semestr, albo cały rejestr transakcji z konkretnego okresu, gdy nie odnosisz się już do większego zbioru. Wtedy użycie funkcji populacyjnej daje bardziej logiczny wynik niż sztuczne traktowanie danych jako próby.
Jeśli nadal masz wątpliwość, przyjmuję prostą zasadę: gdy nie jestem pewien, że mam komplet wszystkich danych, liczę wariant dla próbki. To ustawienie pasuje do większości raportów, analiz szkolnych i biznesowych, bo w realnej pracy rzadko operuje się naprawdę pełną populacją. Kiedy to rozróżnienie jest jasne, warto zobaczyć błędy, które najczęściej psują wynik.
Najczęstsze błędy, które zniekształcają wynik
Odchylenie standardowe samo w sobie nie jest trudne. Problemy pojawiają się wtedy, gdy dane są źle przygotowane albo funkcja została dobrana z rozpędu. W praktyce powtarzają się te same potknięcia i warto je od razu wyłapać, bo potrafią całkowicie zmienić interpretację.
- Mylenie próbki z populacją - to najczęstszy błąd i jednocześnie najbardziej kosztowny, jeśli wynik ma trafić do raportu.
- Tekst w zakresie danych - zwykłe funkcje statystyczne ignorują tekst w komórkach, więc liczba może wyjść poprawna, ale niepełna z Twojego punktu widzenia.
- Wartości zapisane jako tekst - Excel czasem nie traktuje ich jak liczb, więc wynik może być zaniżony albo błędny bez wyraźnego komunikatu.
- Puste komórki i dziury w zakresie - same w sobie zwykle nie są problemem, ale często sygnalizują, że zakres został źle wskazany.
- Porównywanie danych w różnych jednostkach - odchylenie 5 przy średniej 20 i odchylenie 5 przy średniej 500 to zupełnie inna sytuacja analityczna.
- Zbyt mało obserwacji - przy kilku punktach danych wynik jest mało stabilny i lepiej traktować go jako sygnał niż twardy wniosek.
Jeśli w danych masz też wartości logiczne albo tekstowe reprezentacje liczb i chcesz, by zostały uwzględnione, użyj wersji z końcówką .A. To drobny detal, ale w mieszanych arkuszach właśnie on często decyduje o tym, czy wynik odzwierciedla rzeczywistość. Na końcu zostaje interpretacja, bo sama liczba bez kontekstu bywa myląca.
Co jeszcze sprawdzam, zanim uznam wynik za gotowy
Sam wynik odchylenia standardowego nie mówi jeszcze, czy dane są dobre, złe, stabilne czy chaotyczne. Mówi tylko, jak szeroko wartości rozchodzą się wokół średniej, więc trzeba go czytać razem ze skalą danych i z ich liczbą. Ja zawsze patrzę na to w kilku krokach, zanim wpiszę wynik do raportu albo wyślę go dalej.
- Czy użyłem właściwej funkcji - próbki, populacji albo wersji z końcówką .A, jeśli zakres nie jest czysto liczbowy.
- Czy zakres obejmuje dokładnie to, co chcę analizować - bez przypadkowych nagłówków, sum pośrednich i obcych kolumn.
- Czy jednostki są spójne - nie porównuję ze sobą wartości w złotówkach, procentach i sztukach, jakby były tym samym typem danych.
- Czy wynik ma sens na tle średniej - odchylenie 3 przy średniej 6 oznacza coś zupełnie innego niż odchylenie 3 przy średniej 300.
- Czy nie mam wartości odstających - pojedynczy skrajny wynik potrafi wyraźnie podbić rozrzut, więc czasem warto spojrzeć też na medianę lub wykres punktowy.
- Czy liczba obserwacji jest wystarczająca - im mniej danych, tym mniej pewny jest wniosek, nawet jeśli formuła działa bezbłędnie.
W praktyce najlepszy nawyk jest prosty: najpierw wybieram właściwą funkcję, potem sprawdzam zakres i typ danych, a dopiero na końcu interpretuję liczbę. To wystarczy, żeby Excel stał się narzędziem do realnej analizy, a nie tylko miejscem do mechanicznego liczenia rozrzutu. Jeśli pracujesz na raportach cyklicznych, trzymaj obok wyniku także średnią i liczbę obserwacji, bo bez tego nawet poprawnie policzone odchylenie łatwo wyciągnie zbyt daleko idące wnioski.